Java Universal Network/Graph Framework
Posted: September 15, 2009 Filed under: Research | Tags: graph, java, jung, visualization tools 2 CommentsRecently, I’m primarily concerned with large-scale graph data processing. Occasionally, the visualization of graph can be a good way for us to observe some properties from graph data sets. Today, I’m going to introduce a graph framework, called Java Universal Network/Graph Framework (Jung). Jung provides data structures for graph, a programming interface familiar with graph features, some fundamental graph algorithms (e.g., minimum spanning tree, depth-first search, breath-first search, and dijkstra algorithm), and even visualization methods. Especially, I’m interested in its visualization methods.
The following java source shows the programming interface of Jung. In more detail, this program make a graph, add three vertices to the graph, and connect vertices. This source code is brought from Jung tutorial. As you can see, Jung’s APIs are very easy.
// Make a graph by a SparseMultigraph instance.
Graph<Integer, String> g = new SparseMultigraph<Integer, String>();
g.addVertex((Integer)1); // Add a vertex with an integer 1
g.addVertex((Integer)2);
g.addVertex((Integer)3);
g.addEdge("Edge-A", 1,3); // Added an edge to connect between 1 and 3 vertices.
g.addEdge("Edge-B", 2,3, EdgeType.DIRECTED);
g.addEdge("Edge-C", 3, 2, EdgeType.DIRECTED);
g.addEdge("Edge-P", 2,3); // A parallel edge
// Make some objects for graph layout and visualization.
Layout<Integer, String> layout = new KKLayout<Integer, String>(g);
BasicVisualizationServer<Integer, String> vv =
new BasicVisualizationServer<Integer, String>(layout);
vv.setPreferredSize(new Dimension(800,800));
// It determine how each vertex with its value is represented in a diagram.
ToStringLabeller<Integer> vertexPaint = new ToStringLabeller<Integer>() {
public String transform(Integer i) {
return ""+i;
}
};
vv.getRenderContext().setVertexLabelTransformer(vertexPaint);
JFrame frame = new JFrame("Simple Graph View");
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.getContentPane().add(vv);
frame.pack();
frame.setVisible(true);
Some APIs of the Jung are based on generic programming, so you can use easily vertices or edges to contains user-defined data. If you want more detail information, visit http://jung.sourceforge.net.
The above source code shows the following diagram.

Zipf Distribution Random Generator in Java
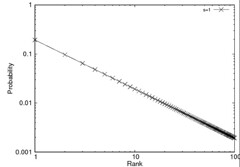
Posted: September 13, 2009 Filed under: Research | Tags: distribution, java, probability, zipf 12 CommentsWhen I carry out some experiments, I usually make synthetic data sets generated by some probability distributions. Especially, Zipf distribution is frequently used for a synthetic data set. Zipf distribution is one of the discrete power law probability distributions. You can get detail information from Zipf’s law in Wikipedia. Anyway, I attached my own java class for zip distribution. Below graphs are generated by my own java code and the gnuplot.
import java.util.Random; public class ZipfGenerator { private Random rnd = new Random(System.currentTimeMillis()); private int size; private double skew; private double bottom = 0; public ZipfGenerator(int size, double skew) { this.size = size; this.skew = skew; for(int i=1;i < size; i++) { this.bottom += (1/Math.pow(i, this.skew)); } } // the next() method returns an random rank id. // The frequency of returned rank ids are follows Zipf distribution. public int next() { int rank; double friquency = 0; double dice; rank = rnd.nextInt(size); friquency = (1.0d / Math.pow(rank, this.skew)) / this.bottom; dice = rnd.nextDouble(); while(!(dice < friquency)) { rank = rnd.nextInt(size); friquency = (1.0d / Math.pow(rank, this.skew)) / this.bottom; dice = rnd.nextDouble(); } return rank; } // This method returns a probability that the given rank occurs. public double getProbability(int rank) { return (1.0d / Math.pow(rank, this.skew)) / this.bottom; } public static void main(String[] args) { if(args.length != 2) { System.out.println("usage: ./zipf size skew"); System.exit(-1); } ZipfGenerator zipf = new ZipfGenerator(Integer.valueOf(args[0]), Double.valueOf(args[1])); for(int i=1;i <= 100; i++) System.out.println(i+" "+zipf.getProbability(i)); } }

One-column abstract in two-column layouts in articles on Latex
Posted: September 11, 2009 Filed under: Research | Tags: abstract, latex, one-column, two-column 1 CommentIf you want one-column abstract in two-column layouts in articles on Latex, just add abstract package and follow below source code. Someone who uses ubuntu linux can install the abstract package from ‘texlive-latex-extra’ package via synaptic. Others can install from http://www.tex.ac.uk/tex-archive/macros/latex/contrib/abstract/
usepackage{abstract}
twocolumn[
maketitle
begin{onecolabstract}
Here in which one-column abstract resides
end{onecolabstract}
]
You should move ‘maketitle’ within ‘twocolumn’ like above code and remove ‘abstract’.
You can find further information about the abstract package from http://www.tex.ac.uk/tex-archive/macros/latex/contrib/abstract/abstract.pdf.
